Why Neo4j Leads the Graph Database Models
The goal of this post is to introduce graph databases in general and Neo4j in particular. As a prerequisite, it is advised to read our white paper that takes you through the different types of NoSQL databases, including graph databases. While relational databases (RDBMS) boomed in 1980s, graph databases did not enjoy a greater advantage over the former, until recently. Necessity to manage increasing volumes of data, address frequent schema changes, facilitate real-time query response, intelligent data activation requirements were some of the factors that made people realize the advantages of the graph model.
What is a graph database?
Every organization requires a database technology that natively stores relationship information as a first-class entity. While other databases compute relationships expensively at query time, graph databases consider relationships as the key aspect of data, and utilize the relationships effectively to manage highly connected data and complex queries.
In simple terms, graph database is a technology that treats and stores relationship information as a first-class entity. Graph databases offer superior performance for querying data, update data in real-time and support queries simultaneously. They enable problem-solving, provide flexible graph models for grouping and aggregating relevant data, and deliver well-structured relational information between entities.
Neo4j is the most popular graph database in vogue today, which is being used by thousands of organizations across several industries, including retail, manufacturing, government, fraud detection and security, financial services, life sciences and so on.
Advantages of working with Neo4j
Neo4j is an open-source NoSQL graph database that enables ACID-compliant transactions, supporting a friendly query language. Compared to relational databases, Neo4j offers superior performance in retrieving data based on relations to various levels, and provides cluster support and runtime failover. All these features make it suitable to use graph data in production scenarios.
Basic components of Neo4j
Neo4j is often termed as the native graph database because it follows the “property graph model”. The building blocks of the property graph include nodes, relationships and labels.
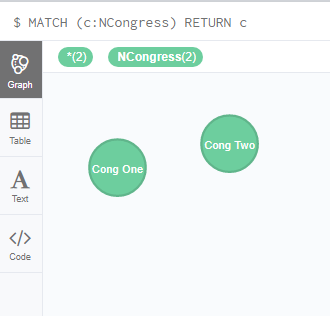
- Nodes: Nodes refer to the entities of a graph, that can hold any number of attributes (properties). A Node, in Neo4j graph is a combination of a Label and few properties. Nodes are used to represent an entity. Following image shows the simplest possible graph in Neo4j.
Syntax:
CREATE ( : < label_name > { < node_properties > })
Example:
CREATE (n1: NCongress {Name : “Congress March2000”})
- Labels: Label is a name used to group Nodes. For instance, a table name in the relational database can be compared to a label in the graph database.
Example:
: NCongress
- Relationships: Relationship defines the connection between Nodes under same or different Labels. A relation may be defined based on the property values of various Nodes.
Example:
: SUBMITTED_BY
A typical use case with Neo4j
Let us consider the example of a graph showing relations between various congresses held during 2012 and 2013, and the abstracts submitted by several experts during those congresses.
Step 1- Node Creation
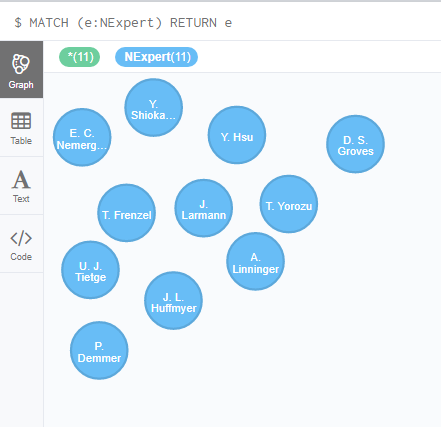
First of all, let us create some Nodes under Label NExpert:
CREATE (n1: NExpert { Name : “J. Larmann”})
CREATE (n2: NExpert { Name : “T. Frenzel”})
CREATE (n3: NExpert { Name : “P. Demmer”})
CREATE (n4: NExpert { Name : “U. J. Tietge”})
CREATE (n5: NExpert { Name : “J. L. Huffmyer”})
CREATE (n6: NExpert { Name : “D. S. Groves”})
CREATE (n7: NExpert { Name : “E. C. Nemergut”})
CREATE (n8: NExpert { Name : “Y. Hsu”})
CREATE (n9: NExpert { Name : “A. Linninger”})
CREATE (n10: NExpert { Name : “T. Yorozu”})
CREATE (n11: NExpert { Name : “Y. Shiokawa”})
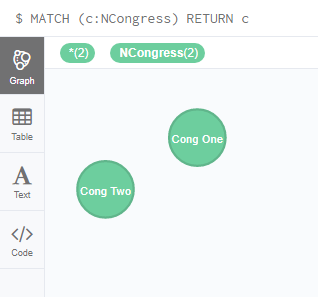
Next step is to create some congresses under Label NCongress.
CREATE (n1: NCongress { Name :”Cong One”, Year :”2012″})
CREATE (n2: NCongress { Name : “Cong Two”, Year :”2013″})
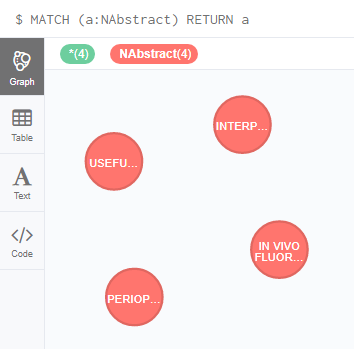
Now let’s create some abstracts under the Label NAbstract, submitted by those Experts.
CREATE (n1: NAbstract { Name :”IN VIVO FLUORESCENCE-MEDIATED TOMOGRAPHY IMAGING DEMONSTRATES ATORVASTATIN MEDIATED REDUCTION OF LESION MACROPHAGES IN APOE-DEFICIENT MICE”, CongressName : “Cong One”})
CREATE (n2: NAbstract { Name :”PERIOPERATIVE USE OF THE GLUCOMMANDER® FOR GLUCOSE CONTROL IN PATIENTS UNDERGOING CARDIAC SURGERY”, CongressName : “Cong One”})
CREATE (n3: NAbstract { Name :”INTERPATIENT VARIABILITY IN INTRATHECAL DRUG DISTRIBUTION: CEREBROSPINAL FLUID PULSATILE MAGNITUDE, FREQUENCY, SOLUTION BARICITY, AND TOXICITY RISKS”, CongressName : “Cong One”})
CREATE (n4: NAbstract { Name :”USEFULNESS OF ULTRASOUND GUIDED CENTRAL VENOUS INSERTION IS DEPENDENT ON THE DIFFERENT CLINICAL EXPERIENCES”, CongressName : “Cong Two”})
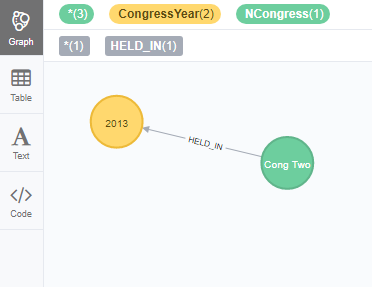
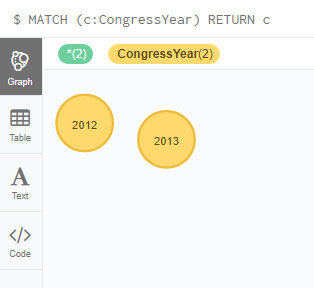
Now, we can create nodes to represent the year on which those congresses were held, under the label ‘CongressYear’.
CREATE (n1: CongressYear{Year : “2012”})
CREATE (n2: CongressYear{Year : “2013”})
With these steps, we are done with the creation of Nodes required for drawing the graph. Next task is to define the relation between required nodes.
Step 2- Defining Relationships
Relationships can be defined in two ways- through generic conditions, or through specific conditions. Both cases are explained below:
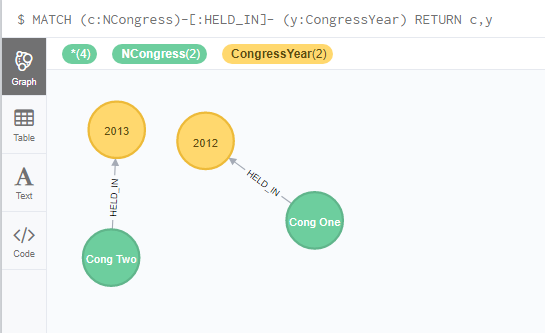
Let’s create a generic condition to define a relationship between the congress and its date
MATCH (c:NCongress), (y: CongressYear)
WHERE c.Year = y.Year
CREATE UNIQUE (c)-[r:HELD_IN]-(y)
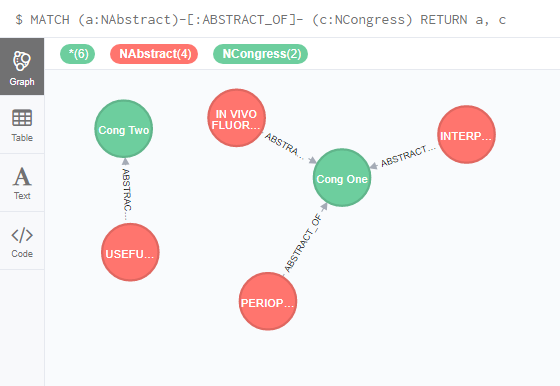
Let’s create a generic condition to define a relationship between the congress and its abstracts
MATCH (c:NCongress), (a: NAbstract)
WHERE c.Name = a.CongressName
CREATE UNIQUE (a)-[r:ABSTRACT_OF]-(c)
The second method is to create the relation between Abstracts and Experts:
MATCH (a:NAbstract ), (e:NExpert )
WHERE a.Name = “IN VIVO FLUORESCENCE-MEDIATED TOMOGRAPHY IMAGING DEMONSTRATES ATORVASTATIN MEDIATED REDUCTION OF LESION MACROPHAGES IN APOE-DEFICIENT MICE”
AND e.Name IN [“J. Larmann”, “T. Frenzel”, “P. Demmer”, “U. J. Tietge”]
CREATE UNIQUE (a)-[r:SUBMITTED_BY]-(e)
MATCH (a:NAbstract ), (e:NExpert )
WHERE a.Name = “PERIOPERATIVE USE OF THE GLUCOMMANDER® FOR GLUCOSE CONTROL IN PATIENTS UNDERGOING CARDIAC SURGERY”
AND e.Name IN [“J. L. Huffmyer”, “Y. Ohashi”, “D. S. Groves”, “E. C. Nemergut”]
CREATE UNIQUE (a)-[r:SUBMITTED_BY]-(e)
MATCH (a:NAbstract ), (e:NExpert )
WHERE a.Name = “INTERPATIENT VARIABILITY IN INTRATHECAL DRUG DISTRIBUTION: CEREBROSPINAL FLUID PULSATILE MAGNITUDE, FREQUENCY, SOLUTION BARICITY, AND TOXICITY RISKS”
AND e.Name IN [“Y. Hsu”, “A. Linninger”]
CREATE UNIQUE (a)-[r:SUBMITTED_BY]-(e)
MATCH (a:NAbstract ), (e:NExpert )
WHERE a.Name = “USEFULNESS OF ULTRASOUND GUIDED CENTRAL VENOUS INSERTION IS DEPENDENT ON THE DIFFERENT CLINICAL EXPERIENCES”
AND e.Name IN [“T. Yorozu”, “Y. Shiokawa”, “J. Larmann”, “Y. Ohashi”]
CREATE UNIQUE (a)-[r:SUBMITTED_BY]-(e)
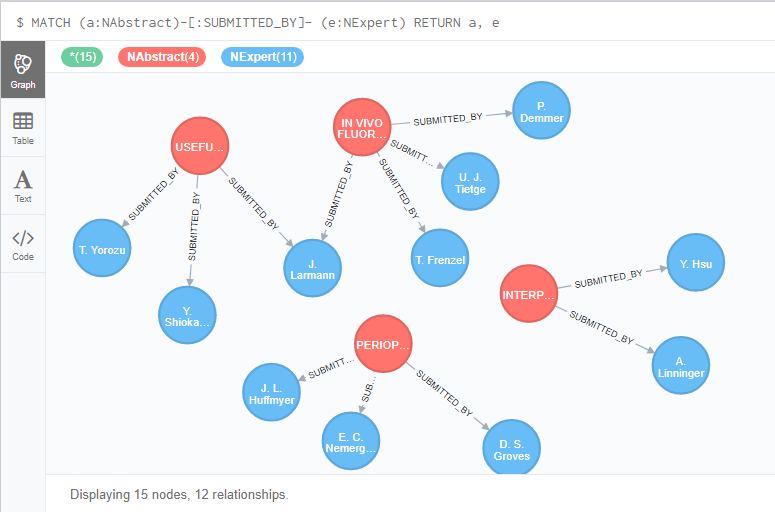
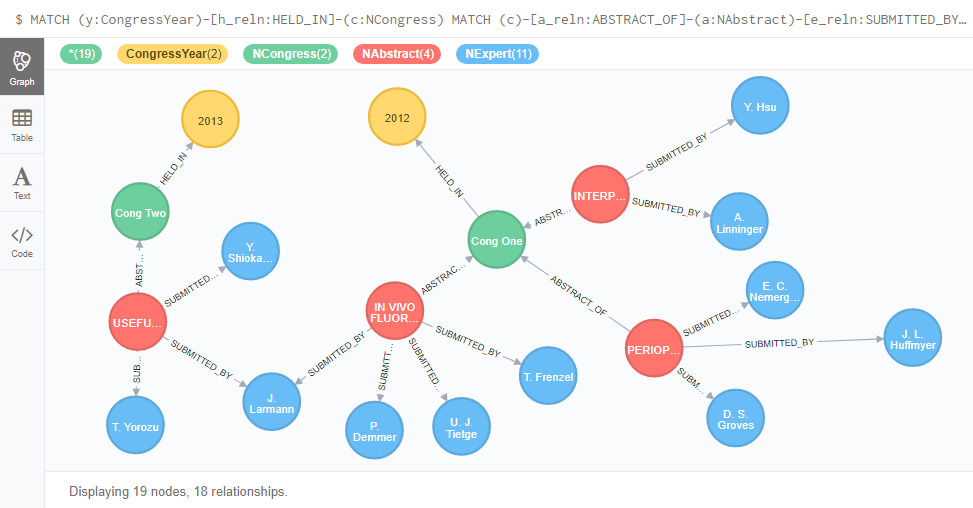
Now the Nodes and their Relationships are ready. The query for selecting and matching those relations appears as given below:
MATCH (y:ReleaseYear)-[r_reln:RELEASED_IN]-(f:Film)
MATCH (a:Actor)-[a_reln:ACTED_IN]-(f)
RETURN y, f, a
The result of the query will appear as shown here:
Neo4j is the world’s first graph database built with native graph storage and processing features. It is equipped to deliver unparalleled performance even as your data grows in enormous proportions.
We at Zerone-consulting would love to know what you think about this article in the comments section below.
We can help!

Ibm Integration Bus: Internal Structure
#Technology
Integrating Openstreetmap To Your Website
#Technology
